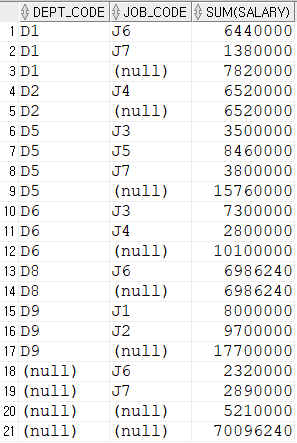
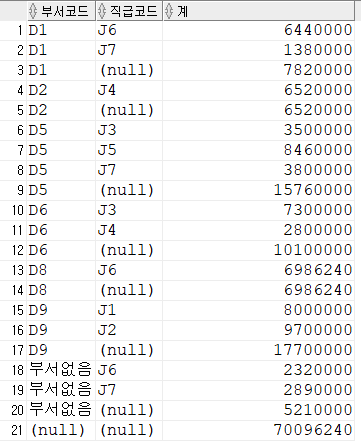
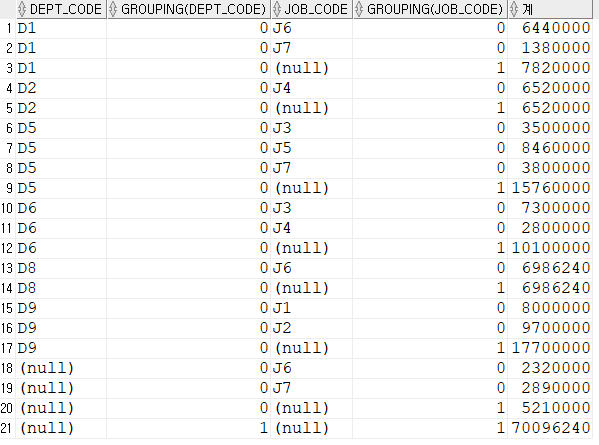
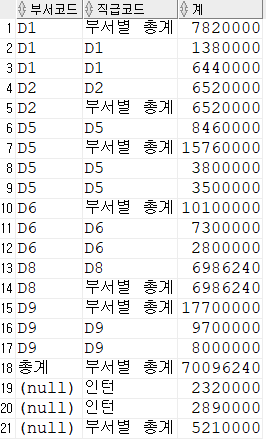
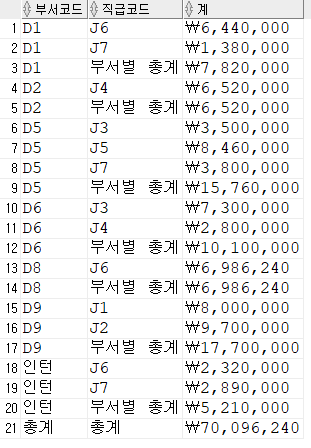
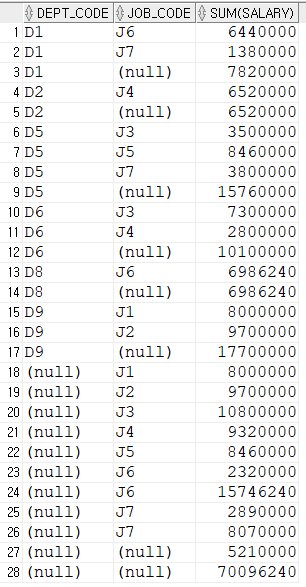
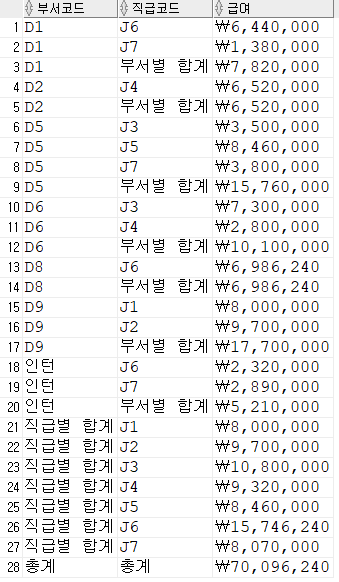
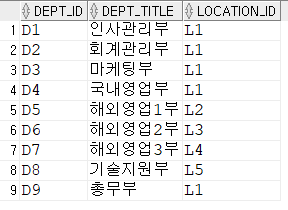
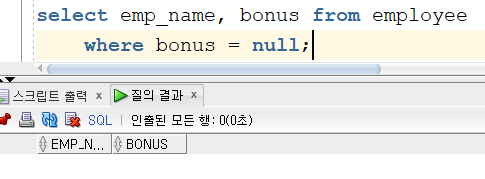
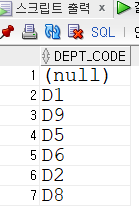
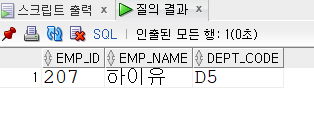
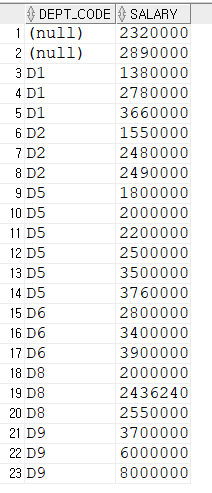
DROP TABLE EMPLOYEE;
DROP TABLE DEPARTMENT;
DROP TABLE JOB;
DROP TABLE LOCATION;
DROP TABLE NATIONAL;
DROP TABLE SAL_GRADE;
--------------------------------------------------------
-- DDL for Table DEPARTMENT
--------------------------------------------------------
CREATE TABLE "KH"."DEPARTMENT"
( "DEPT_ID" CHAR(2 BYTE),
"DEPT_TITLE" VARCHAR2(35 BYTE),
"LOCATION_ID" CHAR(2 BYTE)
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
COMMENT ON COLUMN "KH"."DEPARTMENT"."DEPT_ID" IS '부서코드';
COMMENT ON COLUMN "KH"."DEPARTMENT"."DEPT_TITLE" IS '부서명';
COMMENT ON COLUMN "KH"."DEPARTMENT"."LOCATION_ID" IS '지역코드';
COMMENT ON TABLE "KH"."DEPARTMENT" IS '부서';
REM INSERTING into KH.DEPARTMENT
SET DEFINE OFF;
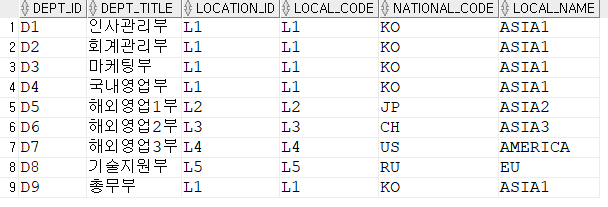
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D1','인사관리부','L1');
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D2','회계관리부','L1');
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D3','마케팅부','L1');
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D4','국내영업부','L1');
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D5','해외영업1부','L2');
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D6','해외영업2부','L3');
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D7','해외영업3부','L4');
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D8','기술지원부','L5');
Insert into KH.DEPARTMENT (DEPT_ID,DEPT_TITLE,LOCATION_ID) values ('D9','총무부','L1');
--------------------------------------------------------
-- DDL for Index 엔터티1_PK2
--------------------------------------------------------
CREATE UNIQUE INDEX "KH"."엔터티1_PK2" ON "KH"."DEPARTMENT" ("DEPT_ID")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
--------------------------------------------------------
-- Constraints for Table DEPARTMENT
--------------------------------------------------------
ALTER TABLE "KH"."DEPARTMENT" ADD CONSTRAINT "DEPARTMENT_PK" PRIMARY KEY ("DEPT_ID")
USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ENABLE;
ALTER TABLE "KH"."DEPARTMENT" MODIFY ("LOCATION_ID" NOT NULL ENABLE);
ALTER TABLE "KH"."DEPARTMENT" MODIFY ("DEPT_ID" NOT NULL ENABLE);
--------------------------------------------------------
-- DDL for Table EMPLOYEE
--------------------------------------------------------
CREATE TABLE "KH"."EMPLOYEE"
( "EMP_ID" VARCHAR2(3 BYTE),
"EMP_NAME" VARCHAR2(20 BYTE),
"EMP_NO" CHAR(14 BYTE),
"EMAIL" VARCHAR2(25 BYTE),
"PHONE" VARCHAR2(12 BYTE),
"DEPT_CODE" CHAR(2 BYTE),
"JOB_CODE" CHAR(2 BYTE),
"SAL_LEVEL" CHAR(2 BYTE),
"SALARY" NUMBER,
"BONUS" NUMBER,
"MANAGER_ID" VARCHAR2(3 BYTE),
"HIRE_DATE" DATE,
"ENT_DATE" DATE,
"ENT_YN" CHAR(1 BYTE) DEFAULT 'N'
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
COMMENT ON COLUMN "KH"."EMPLOYEE"."EMP_ID" IS '사원번호';
COMMENT ON COLUMN "KH"."EMPLOYEE"."EMP_NAME" IS '직원명';
COMMENT ON COLUMN "KH"."EMPLOYEE"."EMP_NO" IS '주민등록번호';
COMMENT ON COLUMN "KH"."EMPLOYEE"."EMAIL" IS '이메일';
COMMENT ON COLUMN "KH"."EMPLOYEE"."PHONE" IS '전화번호';
COMMENT ON COLUMN "KH"."EMPLOYEE"."DEPT_CODE" IS '부서코드';
COMMENT ON COLUMN "KH"."EMPLOYEE"."JOB_CODE" IS '직급코드';
COMMENT ON COLUMN "KH"."EMPLOYEE"."SAL_LEVEL" IS '급여등급';
COMMENT ON COLUMN "KH"."EMPLOYEE"."SALARY" IS '급여';
COMMENT ON COLUMN "KH"."EMPLOYEE"."BONUS" IS '보너스율';
COMMENT ON COLUMN "KH"."EMPLOYEE"."MANAGER_ID" IS '관리자사번';
COMMENT ON COLUMN "KH"."EMPLOYEE"."HIRE_DATE" IS '입사일';
COMMENT ON COLUMN "KH"."EMPLOYEE"."ENT_DATE" IS '퇴사일';
COMMENT ON COLUMN "KH"."EMPLOYEE"."ENT_YN" IS '재직여부';
COMMENT ON TABLE "KH"."EMPLOYEE" IS '사원';
REM INSERTING into KH.EMPLOYEE
SET DEFINE OFF;
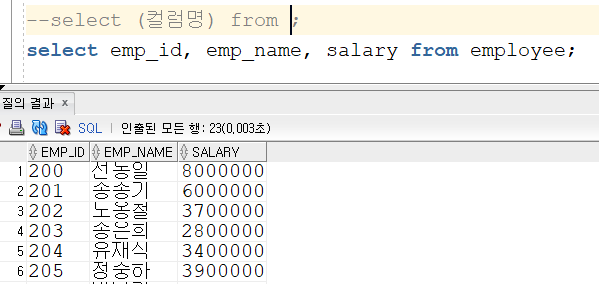
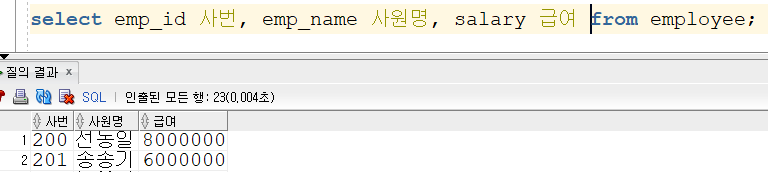
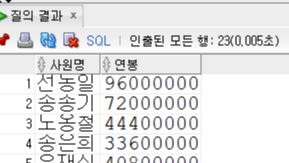
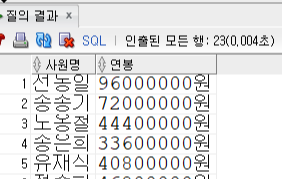
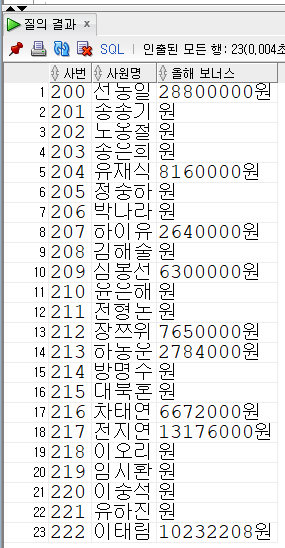
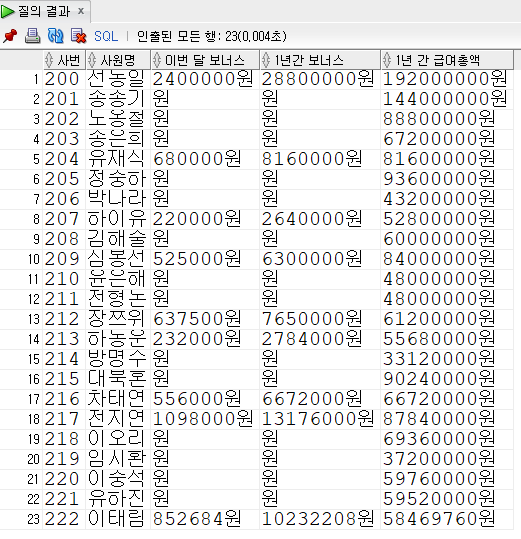
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('200','선동일','621235-1985634','sun_di@kh.or.kr','01099546325','D9','J1','S1',8000000,0.3,null,to_date('90/02/06','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('201','송종기','631156-1548654','song_jk@kh.or.kr','01045686656','D9','J2','S1',6000000,null,'200',to_date('01/09/01','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('202','노옹철','861015-1356452','no_hc@kh.or.kr','01066656263','D9','J2','S4',3700000,null,'201',to_date('01/01/01','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('203','송은희','631010-2653546','song_eh@kh.or.kr','01077607879','D6','J4','S5',2800000,null,'204',to_date('96/05/03','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('204','유재식','660508-1342154','yoo_js@kh.or.kr','01099999129','D6','J3','S4',3400000,0.2,'200',to_date('00/12/29','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('205','정중하','770102-1357951','jung_jh@kh.or.kr','01036654875','D6','J3','S4',3900000,null,'204',to_date('99/09/09','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('206','박나라','630709-2054321','pack_nr@kh.or.kr','01096935222','D5','J7','S6',1800000,null,'207',to_date('08/04/02','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('207','하이유','690402-2040612','ha_iy@kh.or.kr','01036654488','D5','J5','S5',2200000,0.1,'200',to_date('94/07/07','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('208','김해술','870927-1313564','kim_hs@kh.or.kr','01078634444','D5','J5','S5',2500000,null,'207',to_date('04/04/30','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('209','심봉선','750206-1325546','sim_bs@kh.or.kr','0113654485','D5','J3','S4',3500000,0.15,'207',to_date('11/11/11','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('210','윤은해','650505-2356985','youn_eh@kh.or.kr','0179964233','D5','J7','S5',2000000,null,'207',to_date('01/02/03','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('211','전형돈','830807-1121321','jun_hd@kh.or.kr','01044432222','D8','J6','S5',2000000,null,'200',to_date('12/12/12','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('212','장쯔위','780923-2234542','jang_zw@kh.or.kr','01066682224','D8','J6','S5',2550000,0.25,'211',to_date('15/06/17','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('213','하동운','621111-1785463','ha_dh@kh.or.kr','01158456632',null,'J6','S5',2320000,0.1,null,to_date('99/12/31','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('214','방명수','856795-1313513','bang_ms@kh.or.kr','01074127545','D1','J7','S6',1380000,null,'200',to_date('10/04/04','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('215','대북혼','881130-1050911','dae_bh@kh.or.kr','01088808584','D5','J5','S4',3760000,null,null,to_date('17/06/19','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('216','차태연','770808-1364897','cha_ty@kh.or.kr','01064643212','D1','J6','S5',2780000,0.2,'214',to_date('13/03/01','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('217','전지연','770808-2665412','jun_jy@kh.or.kr','01033624442','D1','J6','S4',3660000,0.3,'214',to_date('07/03/20','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('218','이오리','870427-2232123','loo_or@kh.or.kr','01022306545',null,'J7','S5',2890000,null,null,to_date('16/11/28','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('219','임시환','660712-1212123','im_sw@kh.or.kr',null,'D2','J4','S6',1550000,null,null,to_date('99/09/09','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('220','이중석','770823-1113111','lee_js@kh.or.kr',null,'D2','J4','S5',2490000,null,null,to_date('14/09/18','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('221','유하진','800808-1123341','yoo_hj@kh.or.kr',null,'D2','J4','S5',2480000,null,null,to_date('94/01/20','RR/MM/DD'),null,'N');
Insert into KH.EMPLOYEE (EMP_ID,EMP_NAME,EMP_NO,EMAIL,PHONE,DEPT_CODE,JOB_CODE,SAL_LEVEL,SALARY,BONUS,MANAGER_ID,HIRE_DATE,ENT_DATE,ENT_YN) values ('222','이태림','760918-2854697','lee_tr@kh.or.kr','01033000002','D8','J6','S5',2436240,0.35,'100',to_date('97/09/12','RR/MM/DD'),to_date('17/09/12','RR/MM/DD'),'Y');
--------------------------------------------------------
-- DDL for Index 엔터티1_PK
--------------------------------------------------------
CREATE UNIQUE INDEX "KH"."엔터티1_PK" ON "KH"."EMPLOYEE" ("EMP_ID")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
--------------------------------------------------------
-- Constraints for Table EMPLOYEE
--------------------------------------------------------
ALTER TABLE "KH"."EMPLOYEE" ADD CONSTRAINT "EMPLOYEE_PK" PRIMARY KEY ("EMP_ID")
USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ENABLE;
ALTER TABLE "KH"."EMPLOYEE" MODIFY ("SAL_LEVEL" NOT NULL ENABLE);
ALTER TABLE "KH"."EMPLOYEE" MODIFY ("JOB_CODE" NOT NULL ENABLE);
ALTER TABLE "KH"."EMPLOYEE" MODIFY ("EMP_NO" NOT NULL ENABLE);
ALTER TABLE "KH"."EMPLOYEE" MODIFY ("EMP_NAME" NOT NULL ENABLE);
ALTER TABLE "KH"."EMPLOYEE" MODIFY ("EMP_ID" NOT NULL ENABLE);
--------------------------------------------------------
-- DDL for Table JOB
--------------------------------------------------------
CREATE TABLE "KH"."JOB"
( "JOB_CODE" CHAR(2 BYTE),
"JOB_NAME" VARCHAR2(35 BYTE)
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
COMMENT ON COLUMN "KH"."JOB"."JOB_CODE" IS '직급코드';
COMMENT ON COLUMN "KH"."JOB"."JOB_NAME" IS '직급명';
COMMENT ON TABLE "KH"."JOB" IS '직급';
REM INSERTING into KH.JOB
SET DEFINE OFF;
Insert into KH.JOB (JOB_CODE,JOB_NAME) values ('J1','대표');
Insert into KH.JOB (JOB_CODE,JOB_NAME) values ('J2','부사장');
Insert into KH.JOB (JOB_CODE,JOB_NAME) values ('J3','부장');
Insert into KH.JOB (JOB_CODE,JOB_NAME) values ('J4','차장');
Insert into KH.JOB (JOB_CODE,JOB_NAME) values ('J5','과장');
Insert into KH.JOB (JOB_CODE,JOB_NAME) values ('J6','대리');
Insert into KH.JOB (JOB_CODE,JOB_NAME) values ('J7','사원');
--------------------------------------------------------
-- DDL for Index 엔터티1_PK1
--------------------------------------------------------
CREATE UNIQUE INDEX "KH"."엔터티1_PK1" ON "KH"."JOB" ("JOB_CODE")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
--------------------------------------------------------
-- Constraints for Table JOB
--------------------------------------------------------
ALTER TABLE "KH"."JOB" ADD CONSTRAINT "JOB_PK" PRIMARY KEY ("JOB_CODE")
USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ENABLE;
ALTER TABLE "KH"."JOB" MODIFY ("JOB_CODE" NOT NULL ENABLE);
--------------------------------------------------------
-- DDL for Table LOCATION
--------------------------------------------------------
CREATE TABLE "KH"."LOCATION"
( "LOCAL_CODE" CHAR(2 BYTE),
"NATIONAL_CODE" CHAR(2 BYTE),
"LOCAL_NAME" VARCHAR2(40 BYTE)
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
COMMENT ON COLUMN "KH"."LOCATION"."LOCAL_CODE" IS '지역코드';
COMMENT ON COLUMN "KH"."LOCATION"."NATIONAL_CODE" IS '국가코드';
COMMENT ON COLUMN "KH"."LOCATION"."LOCAL_NAME" IS '지역명';
COMMENT ON TABLE "KH"."LOCATION" IS '지역';
REM INSERTING into KH.LOCATION
SET DEFINE OFF;
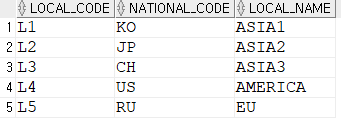
Insert into KH.LOCATION (LOCAL_CODE,NATIONAL_CODE,LOCAL_NAME) values ('L1','KO','ASIA1');
Insert into KH.LOCATION (LOCAL_CODE,NATIONAL_CODE,LOCAL_NAME) values ('L2','JP','ASIA2');
Insert into KH.LOCATION (LOCAL_CODE,NATIONAL_CODE,LOCAL_NAME) values ('L3','CH','ASIA3');
Insert into KH.LOCATION (LOCAL_CODE,NATIONAL_CODE,LOCAL_NAME) values ('L4','US','AMERICA');
Insert into KH.LOCATION (LOCAL_CODE,NATIONAL_CODE,LOCAL_NAME) values ('L5','RU','EU');
--------------------------------------------------------
-- DDL for Index 엔터티1_PK3
--------------------------------------------------------
CREATE UNIQUE INDEX "KH"."엔터티1_PK3" ON "KH"."LOCATION" ("LOCAL_CODE")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
--------------------------------------------------------
-- Constraints for Table LOCATION
--------------------------------------------------------
ALTER TABLE "KH"."LOCATION" ADD CONSTRAINT "LOCATION_PK" PRIMARY KEY ("LOCAL_CODE")
USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ENABLE;
ALTER TABLE "KH"."LOCATION" MODIFY ("NATIONAL_CODE" NOT NULL ENABLE);
ALTER TABLE "KH"."LOCATION" MODIFY ("LOCAL_CODE" NOT NULL ENABLE);
--------------------------------------------------------
-- DDL for Table NATIONAL
--------------------------------------------------------
CREATE TABLE "KH"."NATIONAL"
( "NATIONAL_CODE" CHAR(2 BYTE),
"NATIONAL_NAME" VARCHAR2(35 BYTE)
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
COMMENT ON COLUMN "KH"."NATIONAL"."NATIONAL_CODE" IS '국가코드';
COMMENT ON COLUMN "KH"."NATIONAL"."NATIONAL_NAME" IS '국가명';
COMMENT ON TABLE "KH"."NATIONAL" IS '국가';
REM INSERTING into KH.NATIONAL
SET DEFINE OFF;
Insert into KH.NATIONAL (NATIONAL_CODE,NATIONAL_NAME) values ('KO','한국');
Insert into KH.NATIONAL (NATIONAL_CODE,NATIONAL_NAME) values ('JP','일본');
Insert into KH.NATIONAL (NATIONAL_CODE,NATIONAL_NAME) values ('CH','중국');
Insert into KH.NATIONAL (NATIONAL_CODE,NATIONAL_NAME) values ('US','미국');
Insert into KH.NATIONAL (NATIONAL_CODE,NATIONAL_NAME) values ('RU','러시아');
--------------------------------------------------------
-- DDL for Index 엔터티1_PK4
--------------------------------------------------------
CREATE UNIQUE INDEX "KH"."엔터티1_PK4" ON "KH"."NATIONAL" ("NATIONAL_CODE")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
--------------------------------------------------------
-- Constraints for Table NATIONAL
--------------------------------------------------------
ALTER TABLE "KH"."NATIONAL" ADD CONSTRAINT "NATIONAL_PK" PRIMARY KEY ("NATIONAL_CODE")
USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ENABLE;
ALTER TABLE "KH"."NATIONAL" MODIFY ("NATIONAL_CODE" NOT NULL ENABLE);
--------------------------------------------------------
-- DDL for Table SAL_GRADE
--------------------------------------------------------
CREATE TABLE "KH"."SAL_GRADE"
( "SAL_LEVEL" CHAR(2 BYTE),
"MIN_SAL" NUMBER,
"MAX_SAL" NUMBER
) SEGMENT CREATION IMMEDIATE
PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
COMMENT ON COLUMN "KH"."SAL_GRADE"."SAL_LEVEL" IS '급여등급';
COMMENT ON COLUMN "KH"."SAL_GRADE"."MIN_SAL" IS '최소급여';
COMMENT ON COLUMN "KH"."SAL_GRADE"."MAX_SAL" IS '최대급여';
COMMENT ON TABLE "KH"."SAL_GRADE" IS '급여등급';
REM INSERTING into KH.SAL_GRADE
SET DEFINE OFF;
Insert into KH.SAL_GRADE (SAL_LEVEL,MIN_SAL,MAX_SAL) values ('S1',6000000,10000000);
Insert into KH.SAL_GRADE (SAL_LEVEL,MIN_SAL,MAX_SAL) values ('S2',5000000,5999999);
Insert into KH.SAL_GRADE (SAL_LEVEL,MIN_SAL,MAX_SAL) values ('S3',4000000,4999999);
Insert into KH.SAL_GRADE (SAL_LEVEL,MIN_SAL,MAX_SAL) values ('S4',3000000,3999999);
Insert into KH.SAL_GRADE (SAL_LEVEL,MIN_SAL,MAX_SAL) values ('S5',2000000,2999999);
Insert into KH.SAL_GRADE (SAL_LEVEL,MIN_SAL,MAX_SAL) values ('S6',1000000,1999999);
--------------------------------------------------------
-- DDL for Index 엔터티2_PK
--------------------------------------------------------
CREATE UNIQUE INDEX "KH"."엔터티2_PK" ON "KH"."SAL_GRADE" ("SAL_LEVEL")
PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ;
--------------------------------------------------------
-- Constraints for Table SAL_GRADE
--------------------------------------------------------
ALTER TABLE "KH"."SAL_GRADE" ADD CONSTRAINT "엔터티2_PK" PRIMARY KEY ("SAL_LEVEL")
USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DEFAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ENABLE;
ALTER TABLE "KH"."SAL_GRADE" MODIFY ("SAL_LEVEL" NOT NULL ENABLE);
COMMIT;