- 랭체인의 다양한 모듈 중 하나
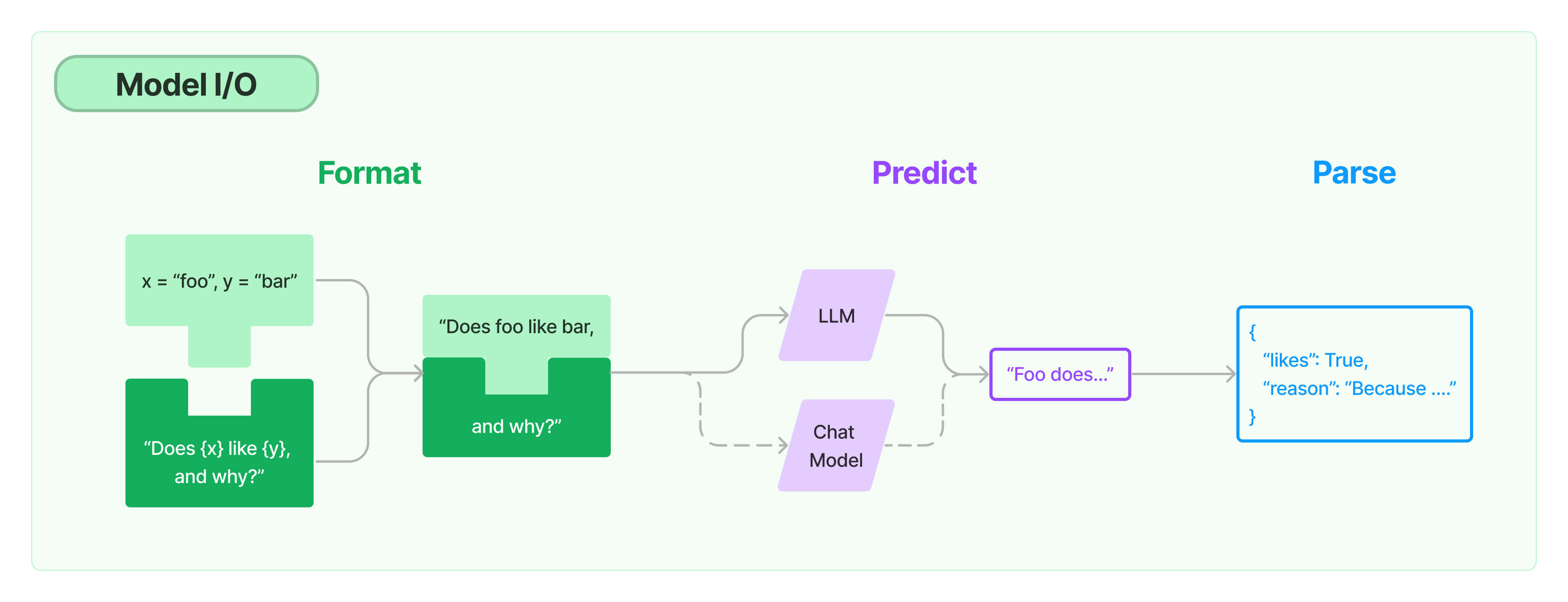
- fewShot : 모델에게 예제를 제공
- 단 예제를 무한히 줄 수는 없음 : 비용문제, 제한존재
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
""",
},
{
"question": "When was the founder of craigslist born?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
""",
},
{
"question": "Who was the maternal grandfather of George Washington?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
""",
},
{
"question": "Are both the directors of Jaws and Casino Royale from the same country?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
""",
},
]
example_prompt = PromptTemplate(
input_variables=["question", "answer"], template="Question: {question}\n{answer}"
)
print(example_prompt.format(**examples[0]))
from langchain_core.prompts import (
ChatPromptTemplate,
FewShotChatMessagePromptTemplate,
)
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]
# This is a prompt template used to format each individual example.
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
print(few_shot_prompt.format())
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a wondrous wizard of math."),
few_shot_prompt,
("human", "{input}"),
]
)
from langchain_community.chat_models import ChatAnthropic
chain = final_prompt | ChatAnthropic(temperature=0.0)
chain.invoke({"input": "What's the square of a triangle?"})
3.1 LengthBasedExampleSelector
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
# Examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = LengthBasedExampleSelector(
# The examples it has available to choose from.
examples=examples,
# The PromptTemplate being used to format the examples.
example_prompt=example_prompt,
# The maximum length that the formatted examples should be.
# Length is measured by the get_text_length function below.
max_length=25,
# The function used to get the length of a string, which is used
# to determine which examples to include. It is commented out because
# it is provided as a default value if none is specified.
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))
)
dynamic_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
# An example with small input, so it selects all examples.
print(dynamic_prompt.format(adjective="big"))
# An example with long input, so it selects only one example.
long_string = "big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else"
print(dynamic_prompt.format(adjective=long_string))
# You can add an example to an example selector as well.
new_example = {"input": "big", "output": "small"}
dynamic_prompt.example_selector.add_example(new_example)
print(dynamic_prompt.format(adjective="enthusiastic"))