디지털 컨버전스/Oracle
[Oracle] Alias, self join, set operator(union, union all, intersect, minus), sequence , DML(delete , update)
gimyeondong
2020. 3. 19. 10:07
JOIN
Natural JOIN - Cartesian Product
Inner JOIN - 조건을 충족하는 결과들만의 집합
Outer JOIN - 조건이 충족되지 않아도 일단 모두 출력하는 집합
조인할 테이블들의 컬럼명이 같을 경우 조인하기 곤란
테이블의 이름 붙여놓기 (as)
-- 조인할 테이블들의 컬럼명이 같으면 조인하기 곤란
-- employee의 job_code, job의 job_code 조인
select
*
from employee, job
where job_code = job_code;
--00918. 00000 - "column ambiguously defined"
-- 컬럼이 모호하게 정의되었습니다.-- 테이블에 별명 붙여놓기 (as)
select
*
from employee emp, job j
where emp.job_code = j.job_code;
select
emp_name, job_name, emp.job_code
from employee emp, job j
where emp.job_code = j.job_code;self join
-- 한 행씩 봤을때 자기 자신이 자신의 직속상사일수 없음
select emp_id , emp_name, Manager_id from employee
where emp_id = manager_id;-- self join도 두 테이블이라고 생각하고 구성
select e1.emp_id, e1.emp_name, e2.emp_name
from employee e1 , employee e2
where e1.manager_id = e2.emp_id;테이블 3개 연결
select
emp_name,
dept_title
from employee e, department d
where e.dept_code = d.dept_id;-- 자바의 3중 for문과 유사한 형태
select
e.emp_name
d.dept_title
d.location_id
from employee e, department d, location l
where
e.dept_code = d.dept_id and
d.location_id = l.local_code;select * from employee;
select * from department;
select * from location;
select * from national;
select
e.emp_name,
d.dept_title,
n.national_name
from employee e, department d, location l, national n
where
e.dept_code = d.dept_id and
d.location_id = l.local_code and
l.national_code = n.national_code;
--ansi 표준
select
e.emp_name,
d.dept_title,
n.national_name
from
employee e join department d on e.dept_code = d.dept_id
join location l on d.location_id = l.local_code
join national n on l.national_code = n.national_code;--outer join
select
e.emp_name,
d.dept_title,
n.national_name
from employee e, department d, location l, national n
where
e.dept_code = d.dept_id(+) and
d.location_id = l.local_code(+) and
l.national_code = n.national_code(+);--각 사원들의 이름 / 나이 / 부서명 / 직급명을 출력하세요.
select
e.emp_name "이름",
extract(year from sysdate)-(decode(substr(e.emp_no,8,1),1,1900,2,1900,3,2000,4,2000)+substr(e.emp_no,1,2)) "나이",
d.dept_title "부서명",
j.job_name "직급명"
from employee e, department d, job j
where
e.dept_code = d.dept_id(+) and
e.job_code = j.job_code(+);
-- 1. 2030년 12월 25일의 요일을 출력하시오
select
to_char(to_date(20301225),'day')
from
dual;-- 2. 주민번호가 1970년대 생이면서 성별이 여자이고,
-- 성이 전씨인 직원들의 사원명, 주민번호, 부서명, 직급명을 조회하세요.
select
e.emp_name "사원명",
e.emp_no "주민번호",
d.dept_title "부서명",
j.job_name "직급명"
from employee e, department d, job j
where
e.dept_code = d.dept_id(+) and
e.job_code = j.job_code(+);-- 3. 이름에 '형' 자가 들어가는 직원들의 사번, 사원명, 부서명을 조회하세요.
select
e.emp_id "사번",
e.emp_name "사원명",
d.dept_title "부서명"
from employee e, department d
where
e.emp_name like '%형%' and
e.dept_code = d.dept_id(+);-- 4. 해외영업부에 근무하는 사원명, 직급명, 부서코드, 부서명을 조회하세요.
select
e.emp_name "사원명",
j.job_name "직급명",
e.dept_code "부서코드",
d.dept_title "부서명"
from employee e, job j, department d
where
d.dept_title like '해외영업%' and
e.job_code = j.job_code and
e.dept_code = d.dept_id;-- 5. 보너스포인트를 받는 직원들의
--사원명, 보너스포인트, 부서명, 근무지역명(나라이름)을 조회하세요
select
e.emp_name "사원명",
e.bonus "보너스포인트",
d.dept_title "부서명",
n.national_name "근무지역명"
from employee e, department d , location l, national n
where
e.bonus is not null and
e.dept_code = d.dept_id and
d.location_id = l.local_code and
l.national_code = n.national_code;-- 6. 부서코드가 D2인 직원들의
-- 사원명, 직급명, 부서명, 근무지역명을 조회하세요.
select
e.emp_name "사원명",
j.job_name "직급명",
d.dept_title "부서명",
n.national_name "근무지역명"
from employee e, job j, department d, location l,national n
where
e.dept_code = 'D2' and
e.job_code = j.job_code and
e.dept_code = d.dept_id and
d.location_id = l.local_code and
l.national_code = n.national_code;-- 7. 급여등급테이블의 최대급여 (MAX_SAL - 500000)보다 많이 받는 직원들의
-- 사원명, 직급명, 급여, 연봉을 죄회하세요.
select
e.emp_name "사원명",
j.job_name "직급명",
e.salary"급여",
e.salary*12 "연봉"
from employee e, job j , SAL_GRADE s
where
e.salary*12>(s.max_sal - 5000000) and
e.job_code = j.job_code and
e.sal_level = s.sal_level ;-- 8. 한국(KO)과 일본(JP)에 근무하는 직원들의
-- 사원명, 부서명, 지역명, 국가명을 조회하세요.
select
e.emp_name "사원명",
d.dept_title "부서명",
l.local_name "지역명",
n.national_name "국가명"
from employee e, department d, location l, national n
where
n. national_code in ('KO','JP') and
e.dept_code = d.dept_id and
d.location_id =l.local_code and
l.national_code = n.national_code;-- 9. 같은 부서에 근무하는 직원들의
-- 사원명, 부서명, 동료이름을 조회하세요. (self join 사용)
-- ex) 홍길동 기술지원부 김철일
-- 홍길동 기술지원부 김철이
-- 홍길동 기술지원부 김철삼
select
e1.emp_name "사원명",
d.dept_title "부서명",
e2.emp_name "동료이름"
from employee e1, department d, employee e2
where
e1.dept_code = d. dept_id and
e1.emp_name !=e2.emp_name
order by 1;-- 10. 보너스포인트가 없는 직원들 중에서 직급이 차장과 사원인 직원들의
-- 사원명, 직급명, 급여를 조회하시오. 단, join과 IN 사용할 것
select
e.emp_name "사원명",
j.job_name "직급명",
e.salary "급여"
from employee e, job j
where
e.bonus is null and
j.job_name in ('차장','사원') and
e.job_code=j.job_code;-- 11. 재직중인 직원과 퇴사한 직원의 수를 조회하시오.
-- 재직여부 인원수
-- 퇴사 1
-- 재직 22
select
decode(ent_yn,'N','재직','Y','퇴사') "재직여부",
count(*) "인원수"
from employee
group by decode(ent_yn,'N','재직','Y','퇴사');-- DQL
-- set operator
-- sub query (중요한 내용이지만 23일 시험 내용에서는 빠짐)
set operator (집합 연산자)
UNION / UNION ALL / INTERSECT / MINUS
select * from employee
union
select * from department;
--"query block has incorrect number of result columns"
--컬럼 개수가 같고 그 자료형이 상호호환 되어야 함--오라클에서 문자열을 숫자로 호환
select '10'+5 from dual;
--15-- 상호호환
select emp_id, emp_name, dept_code from employee
union
select * from department;
--상호호환 안됨
select emp_id, salary, dept_code from employee
union
select * from department;
--"expression must have same datatype as corresponding expression"create table tempA(
temp_col varchar(10)
);
create table tempB(
temp_col varchar(10)
);
insert into tempA values(1);
insert into tempA values(2);
insert into tempA values(3);
select * from tempA;
insert into tempB values(2);
insert into tempB values(3);
insert into tempB values(4);
select * from tempB;union : 중복제거하여 합쳐준다.
-- union : 중복제거하여 합쳐준다.
select * from tempA
union
select * from tempB;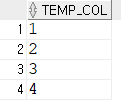
union all : 중복제거 없이 다 합쳐준다.
union all : 중복제거 없이 다 합쳐준다.
select * from tempA
union all
select * from tempB;
intersect : 겹치는 부분만 보여준다.
-- intersect : 겹치는 부분만 보여준다.
select * from tempA
intersect
select * from tempB;
minus : 결과값을 제외
--minus : 결과값을 제외
select * from tempA
minus
select * from tempB;
-- 2, 3은 겹치므로 제외, 4는 원래 없었으니 없음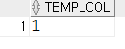
sequence : 순서
값의 순서를 기억하는 객체
create table cafe(
pid number primary key,
pname varchar(30) not null,
price number default 0 not null
);
insert into cafe values(1001,'Americano',2000);
insert into cafe values(1002,'Cafe Latte',2500);
insert into cafe values(1003,'Cafe Mocha',3000);
select * from cafe;--시퀀스 : 값의 순서를 기억하는 객체
-- sequence : 순서
create sequence cafe_seq
start with 1004
increment by 1
nomaxvalue
nocache;
--nocache를 주지 않으면 오라클 시스템이 값을 변경
select sequence_name from user_sequences;
--딕셔너리 : 내린 명령을 기억하는 내장 테이블
insert into cafe values(cafe_seq.nextval,'Caramel macchiato',3500);
DML : 테이블을 대상으로 데이터 수정
delete : 데이터 지우기
--sequence 값을 줄이고 싶을때 : 인위적으로 건드리는 문법 없음
--1. 새로 만들기
--2. increment by를 -로 변경
--DDl 객체 지우기 ; drop
--하나만 지우기 (데이터 DML : delete)
--delete from cafe 는 모든 행을 지우므로, where절로 지울 행 정해주기
delete from cafe where pid=1004;
select * from cafe;
update : 변경하기
--DML : 테이블을 대상으로 데이터 수정
--DML : update
update cafe
set price=3500, pname='Hot choco'
where pid =1003;
select * from cafe;